金融实证研究数据处理:数据对齐的方法论规范与实现逻辑
在现代金融实证研究与量化分析中,数据质量构成了所有计量模型与资产定价检验的基石。无论是构建多因子模型、进行面板数据回归,还是复现复杂的资产定价异象,研究者都必须面对来自多源异构数据库的信息整合问题。其中,“数据对齐”(Data Alignment)不仅是数据清洗的核心环节,更是决定研究结论有效性与稳健性的关键前提。
一、 金融面板数据的维度与对齐基准
金融数据通常具备截面(Cross-sectional)与时间序列(Time-series)的双重属性,构成典型的面板数据结构。在设定对齐基准时,必须确立两个核心主键(Primary Keys):
-
空间维度(实体标识): 上市公司股票代码、基金代码或宏观经济主体。
-
时间维度(时间戳): 交易日历或自然日历。
标准面板回归的基本设定如下:
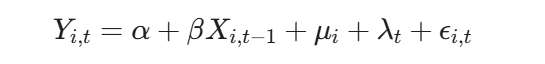
其中,i 代表截面个体,t 代表时间节点。数据对齐的核心目标,即是确保等式两边的被解释变量 Y$与解释变量 X,在绝对且严密的同一 (i, t)$坐标系下精确映射。特别是在预测性回归中(如上述公式体现的滞后期设计),严密的时间对齐是识别因果关系的基础。
二、 数据对齐的核心挑战与异构性处理
实际研究中,从Choice金融终端或CSMAR等数据库获取的原始数据往往存在显著的异构性,主要表现在以下三个维度:
1. 频率错配(Frequency Mismatch)
金融数据的颗粒度差异巨大。微观市场交易数据(如收盘价、成交量)通常为日频(Daily)或高频(Tick);宏观经济变量(如M2增速、CPI)多为月频(Monthly);而企业基本面数据(如资产负债表、利润表核心项目)则为季频(Quarterly)或年频(Annually)。将低频基本面数据对齐至高频交易数据时,绝不能简单采用线性插值,因为这违背了财务信息离散披露的客观规律。
2. 日历基准差异(Calendar Discrepancy)
自然日历与交易日历存在本质区别。由于节假日、周末以及个股层面的停牌与退市,交易时间是不连续的序列。在融合宏观自然月数据,或处理多市场并行数据时,若未能以统一的交易日历作为左表(Left Table)基准进行强制对齐,将导致严重的样本截断或信息错乱。
3. 标识符体系的非标准化
不同数据源对资产的编码规则存在差异。同一只股票在部分终端中可能带有后缀标识(如“000001.SZ”),而在某些本地化清洗后的表格中仅保留纯数字(如“000001”)。此外,系统导出的表头往往夹杂非标准空值(如“–”或“N/A”)。在跨表合并前,必须进行严格的字符串清洗与类型转化,确保唯一标识符的绝对一致与数值类型的纯粹性。
这一点是所有金融数据处理过程中最让人头大的部分,有的时候python报错始终找不到原因很有可能就是由于第一列的code标准不统一导致数据没有对齐!!!
三、 跨期对齐的红线:防范“未来函数”(Look-ahead Bias)
在涉及基本面因子的对齐逻辑中,最大的方法论错误在于引入“未来函数”,即在 $t$ 时刻的分析模型中,使用了 t$时刻之后才被市场真实获知的信息。这在学术界与业界均被视为致命瑕疵。
以复现经典的 QMJ(Quality Minus Junk)因子 为例。该因子的构建需要深度依赖上市公司的财务报表数据,以计算盈利能力、成长性、安全性等维度的截面得分。
-
错误逻辑:基于报表期对齐
若研究者将某公司当年12月31日的日频行情数据,直接与基于同年12月31日“报表期”(End Date)的财务指标对齐,便构成了标准的未来函数。因为12月31日的年度财务数据,通常需要在次年的3月至4月底才通过年报正式披露。在当年的12月末,市场参与者绝对无法获取该项财务信息并以此进行资产定价。
-
学术规范:基于披露期滞后对齐
财务数据的对齐基准必须从“报表期”切换为“实际披露期”(Announce Date)。主流的处理范式包括滞后机制(Lagging)。例如,Fama-French框架在计算 t 年7月至 t+1 年6月的因子暴露时,统一使用 t-1 年12月末的财务数据,强行预留至少6个月的披露缓冲期。更为精细的动态对齐方式,则是利用真实的公告日期字段,在交易日 t 的截面上,仅提取 t$时刻之前最近一次已发布的财务数据。
四、 数据对齐的工程实现逻辑(基于Python生态)
面对海量面板数据,传统的电子表格处理方式在算力与严谨性上均捉襟见肘。利用Python的Pandas库构建自动化的数据处理流,是确保实证过程可复现性的标准路径。
1. 双重索引(MultiIndex)的构建与合并
面板数据清洗的首要步骤是确立面板的二维索引架构。通过将股票代码设定为一级索引,交易日期设定为二级索引,实现数据的正交化结构。在此结构下,运用合并操作能够确保行与行之间在代码与日期的双重约束下精确匹配,从底层逻辑上杜绝错行风险。
2. 时间序列的重采样与频率转换(Resampling)
在处理收益率降频(如日频转月频)时,需严格遵循金融资产的复利特性。其数学表达为计算持有期内的累积收益率:
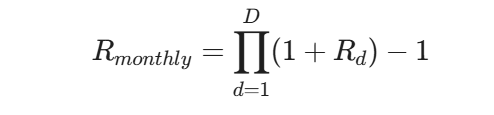
在程序实现上,应通过聚合函数(groupby)结合复利算法,或提取特定周期末的有效交易日价格重新计算差分,而非盲目抓取自然月最后一天的数值。
3. 缺失值的规范处理:向后填充(Forward Fill)
由于财务数据的低频属性或股票停牌,数据在时间轴上必然出现空白。学术规范明确要求,缺失值的填补必须严格采用向后填充(Forward Fill)策略,即假设在新的公告发布前,市场对该主体的基本面认知持续停留在上一次公开信息。严禁使用向前填充(Backward Fill),以免引致未来信息的逆向泄露,破坏面板数据的时间序列因果推断方向。
4. 异步时间戳对齐(As-of Merge)
针对多源非同步时间戳的匹配问题,可采用“最接近合并”逻辑(如Pandas的 merge_asof 方法)。该逻辑允许在严格禁止获取未来数据的前提下,于右表中寻找“距离左表时间点最近,且绝对发生在左表时间点之前”的观测值进行匹配,完美解决了复杂交易日历下的对齐技术瓶颈。
五、 结语
数据对齐绝非机械的表格拼接,其实质是对金融市场信息生成、传递与定价机制的深刻还原。严谨的数据处理流程,要求研究者对数据的底层颗粒度、信息披露的时效限制以及计量经济学常识有敏锐的洞察。在构建多因子模型与实证分析框架时,务必将防范未来函数与保证时间序列的绝对因果方向置于首要位置。唯有建立在逻辑严密、滴水不漏的数据地基之上,后续的实证检验与实证结论,方能具备真正的学术价值与指导意义。